Проектирования высоко нагруженных систем. Часть 1
В процессе разработки одного из проектов перед нашей командой была была поставлена задача спроектировать масштабируемую серверную инфраструктуру для высоко нагруженной клиент-серверной системы с большим объемом хранимой информации.
В ходе анализа задаче перед нами возникло ряд вопросов, которых необходимо было решить и на которые необходимо было получить ответы. Первый вопрос который задался нам: «большой объем информации — большой, это сколько?». На сколько должен быть большим объем, и как должна повести себя система если информация увеличится сразу в двое, это не учитывая репликации и различных бекапов это нам предстояло выяснить. Вторым не менее важным вопросом который интересовал это «высоко нагруженный — какое количество запросов должен обрабатывать сервер для обеспечения работы системы?». Вооружились этими вопросами мы приступили к поиску информации по интересующим вопросам а также набор технологий на которых это можно построить.
Все мы привыкли к тому, что написанное приложение ил же база данных, какой сервис находятся на машинах, за которыми необходимо постоянное наблюдение. Следить за работоспособностью, настраивать устанавливать и многое другое. Однако на сегодняшний день пришло к нам много решений по оптимизации задач похожего уровня. Виртуальные серверы получили большую популярность с открытием сервиса Amazon EC2, когда тебе предоставятся целая инфраструктура для управления. Среди решений IaaS (Infrastructure-as-a-Service - инфраструктура как услуга ) можно встретить набор готовых решений, таких как Cloudstack,vCloud Director, Openstack и другие. Получив такой сервис уже не особо не заботишься о некоторых вещах, поскольку эта задача уже возложена на других. Но в таких решениях очень важную роль играет стоимость принятых решений. Ведь платить за дополнительные не нужные вещи порой обходится очень дорого. С одной стороны ты не заботишься о том как организовать место для хранения данных и добавления очередного места занимает сего лишь один клик в корзине сервиса, а со второй стороны сумма которую приходится за это платить.
Проанализировав построения такой структуры пришли к выводу что это будет дорогостоящим решением и принялись за построения на бесплатных решениях которые сейчас существуют на рынке.
Первым делом мы принялись подсчитать примерный объем данных которые нам необходимо хранить. За один проводимый эксперимент мы получали примерно 400-500 Мб информации за один час работы. К примеру возьмем обычный рабочий день, который длится 8 чесов и мы получим, что за день у нас накапливается примерно 4 Гб информации с одного лишь тестируемого устройства. Но таких устройств, которые будут проводить эксперимент, у нам может за день работать порядка 100 штук, а то и тысячи при необходимости. Таким образом мы получаем дневной объем в 4 Тб информации, которую необходимо хранить в самом минимальном варианте. Но помимо этого нам еще нужно хранить как то эту информацию так, что бы если у нас полетел сервер, то мы ее не потеряли. Ведь неприятно когда выходит диск из строя а у тебя нету резервной копии для продолжения работы. Таким образом нашу сумму можно удваивать в два раза, а в некоторых случаях и три и это при том что не учитывается служебная информация по этим данных.
Поняв примерный объем работы мы приступили к поиску решения. Полазив на просторах интернета мы обнаружили замечательную вещь такую как GlusterFS. Если в двух словах описать то это классная штука которая нам нада. Данная система распространяется под лицензией GPLv3 (до версии 3.1) AGPL (с версии 3.1), что позволяет использовать ее в свои проектах.
На самом деле GlusterFS — это распределенная, параллельная, линейно масштабируемая файловая система с возможностью защиты от сбоев. С помощью данной системы можно объединять различные хранилища данные, находящиеся в различных местах, в одну параллельную сетевую файловую систему. Данная система работает по верх существующих файловых систем (ext3, ext4, xfs и тп.), так в своем распоряжении использует технологию FUSE (Filesystem in Userspace «Файловая система в пользовательском пространстве»). В своем распоряжении система поддерживает репликацию и балансировку нагрузки, что очень важно на сегодняшний день с ростом инфраструктуры.
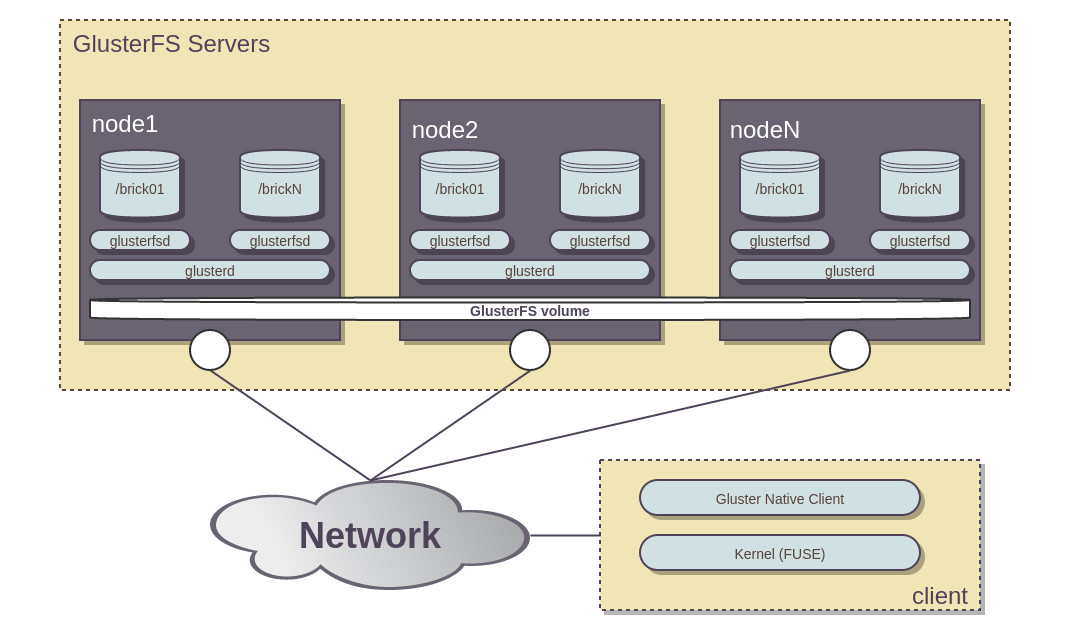
Из плюсов можно выделить:
- минимальные «накладные расходы»
- простота и дешевизна развертывания
- линейно масштабируемая
Таким образом хранить петабайты информации теперь не проблема. У нас в руках мощная штука по управлению данными.
Комментарий (0)